Navigating COVID-19 By The Numbers
17:04 minutes
This story is part of Science Friday’s coverage on the novel coronavirus, the agent of the disease COVID-19. Listen to experts discuss the spread, outbreak response, and treatment.
Ever since the first news about a new virus in China, we’ve been seeing projections, or models predicting how it might spread. But how are those models created? Why do Taiwan and New Zealand’s curves look so different from Italy and the United States? How do factors like social distancing, or staying home, change how many people get sick? And will there be a second wave of coronavirus if we relax social distancing measures too soon?
There’s a lot of math that goes into understanding what might come next. Ira turns to a group of scientists who make their living in crunching the numbers—the people who make mathematical models to approximate different scenarios, trying to minimize loss of life. Sarah Cobey from the University of Chicago and Jeffrey Shaman from Columbia University share their work on the past, present and future of coronavirus spread, and explain how to understand the many models all trying to bring clarity to this very difficult pandemic.
Invest in quality science journalism by making a donation to Science Friday.
Sarah Cobey is an associate professor of Ecology & Evolution at the University of Chicago in Chicago, Illinois.
Jeffrey Shaman is a professor of Environmental Health Sciences and director of the Climate and Health Program at Columbia University in New York, New York.
IRA FLATOW: This is “Science Friday.” I’m Ira Flatow. Just one quick note. We’re trying to figure out why people do citizen science or don’t. And this means it’s research time so please help us out at sciencefriday.com/citizenscience.
And now ever since the first words about a new virus spreading around the world reached our ears, we have been seeing projections or models predicting how it would spread, how many people would be infected, you know those curves we keep talking about flattening. Well, just how are these models created? How do factors like social distancing or staying home change their shapes?
And what about the future, the possibility of a second wave of coronavirus? Remember the 1918 flu pandemic we were just discussing? The second wave was everything then. There’s a lot of math that goes into understanding what might come out next so we turn to a group of scientists who make their living in plausible scenarios, people who actually make the models. How can they help us understand the best course of action?
Here to explain are my guest model makers, Dr. Jeffrey Shaman, professor of environmental health science and director of the Climate and Health Program at Columbia University in New York and Dr. Sarah Cobey associate professor of ecology and evolution at the University of Chicago. Welcome both to “Science Friday.”
JEFFREY SHAMAN: Thank you for having me.
SARAH COBEY: Glad to be here.
IRA FLATOW: You’re welcome. Sarah, let me begin with you. And exactly what is the definition of a model?
SARAH COBEY: So I have a fairly philosophical view on this. And I think that anytime someone’s making some claim about what’s happened in the past or what’s going to happen in the future, they’re modeling. The difference is some people are really careful and explicit about their assumptions that go into those explanations of what has happened or what’s going to happen in the future. And we tend to call ourselves professional modelers when we get really hung up on those assumptions and especially when we’re trying to understand these things in a quantitative way.
IRA FLATOW: All right. Let me use a recipe analogy here with the ingredients that goes into baking a cake. What are the ingredients that go into making a model?
JEFFREY SHAMAN: Well, they can be variable. It depends, I suppose, whether you’re making a main course or a dessert. What we sometimes see are models that are built on mathematical equations that try to represent processes, be they physical, or chemical, or biological. But you also have other models that are built using fuzzy logic, or statistics, or any number of other methods that you may hear that try to represent the system and to make some sort of deduction or very often inference based off that system in order to better understand it and then use that information and that understanding possibly to make projections about what might be happening right now or be happening in the future.
IRA FLATOW: Sarah, let me continue with my recipe analogy. If I don’t use the finest ingredients, I’m not getting the finest of cake. How does that pertain to a model?
SARAH COBEY: Yeah. That’s exactly the right analogy. As a professional modeler, I have worked with ingredients of varying quality. And one of the things that is challenging about this situation, especially for modelers I think in the United States, is that a lot of the data streams that we’re working with you were not really developed with this kind of scenario in mind.
And so we spend a lot of time thinking about, maybe more than we would in the kitchen, but a lot of time thinking about how we can compensate I think for deficiencies in the data and building that uncertainty into the models so that when we’re presenting some forecasts, we can say we know that we were undersampling deaths or definitely missing probably most cases most of the time. But still given that, we’re fairly certain that this is a reasonable outcome or this is a reasonable conclusion.
IRA FLATOW: How important is that to get to know as many cases as possible?
SARAH COBEY: It’s definitely important for understanding what the true fatality ratio or what the true virulence of the coronavirus is. It’s also very useful for knowing how many people have been infected, which is going to tell you something about the rate of spread in a population, and potentially how well different interventions are working, and especially how close we might be to that mythical herd immunity. But we have a lot of ways indirectly that we can get at that while not knowing for sure what the asymptomatic fraction is, for instance, or while not knowing exactly how many of the symptomatic cases are being recorded.
IRA FLATOW: Jeffrey, you’re a co-author on work that asked a big question, how many people may have undocumented or undiagnosed cases of COVID-19 and how responsible those people were for spreading the virus. How do you go about answering that question in a model?
JEFFREY SHAMAN: So what we do to make this estimation is we bring in the data. We bring in those confirmed case data, the documented data. And we actually assimilate it into the model that, in effect, educates the model so that it can find the combination of conditions that are called parameters within the model that allow it to best represent what actually went on.
Once we have that solution and we can verify that we’re able to consistently get the correct definition, but when we apply it to the real data we get that solution, we then plug those numbers into the model without the algorithm and without the data and see if it can replicate what actually happened, which is what it’s able to do.
And when we did this, we found that only one in seven persons in China from January 10 to 23rd was being actually documented. 86% were undocumented. And further, we found that, per person, those undocumented infections were, on average, about half as contagious as the documented infections. But because there were so many more of them, they were actually responsible for the lion’s share of the transmission. We also found that there was good evidence of presymptomatic shedding amongst those who did become symptomatic and were documented.
So there were many routes by which this virus could spread silently or in stealth, people not knowing that they’re contagious, not knowing that they have the disease, were going out and about in the community. And they’re doing what you or I would do if we didn’t know we had infection, or if we just had a little sniffle or a mild sore throat. We’d still get on public transportation. We still go to work. We still would take business trips. And by doing that, we’re facilitating the spread of the virus broadly within the community and allowing it to really take off.
IRA FLATOW: Sarah, your work focuses on the rate of spread in the state of Illinois. What are you learning about the rate of spread? And what are the models saying about the effectiveness of different interventions?
SARAH COBEY: So one of the things that’s surprised us is that we’re not seeing dramatic differences in the rate of spread between the more urban and rural regions right now in Illinois. And you know, in some ways, that’s actually not so surprising because there still are high levels of mobility within smaller towns and between towns.
We generally expect cities to be the primary places where a pathogen is going to be introduced, but we’re seeing in Illinois that there’s no place that’s obviously very far behind. And we’re also seeing a really nice impact, as we would hope, because we’re all suffering under stay at home orders right now.
So we’re seeing a very nice impact on those interventions and a large reduction in the reproductive number. It’s probably at least halved. Probably actually it’s gone down even more than that. But we’re also still not quite out of the woods. So I think we have continued shelter in place through the end of May. And I think that’s probably a good idea.
And what kind of variables could influence the answers that you’re getting? We’re spending a lot of time again thinking about how well cases, and hospitalizations, and deaths are reported in different regions. So that right now is probably our biggest source of uncertainty and something that we’re focused on primarily. But there are some general questions that I think modelers all over the world are grappling with that have a huge impact on policy going forward.
For instance, you know, how important are children for spreading the disease and how susceptible are they, and just how do you different age groups and different settings contribute to transmission. That’s the sort of thing that right now we can’t really deconvolve or pull out of our models but will be extremely important to understand going forward.
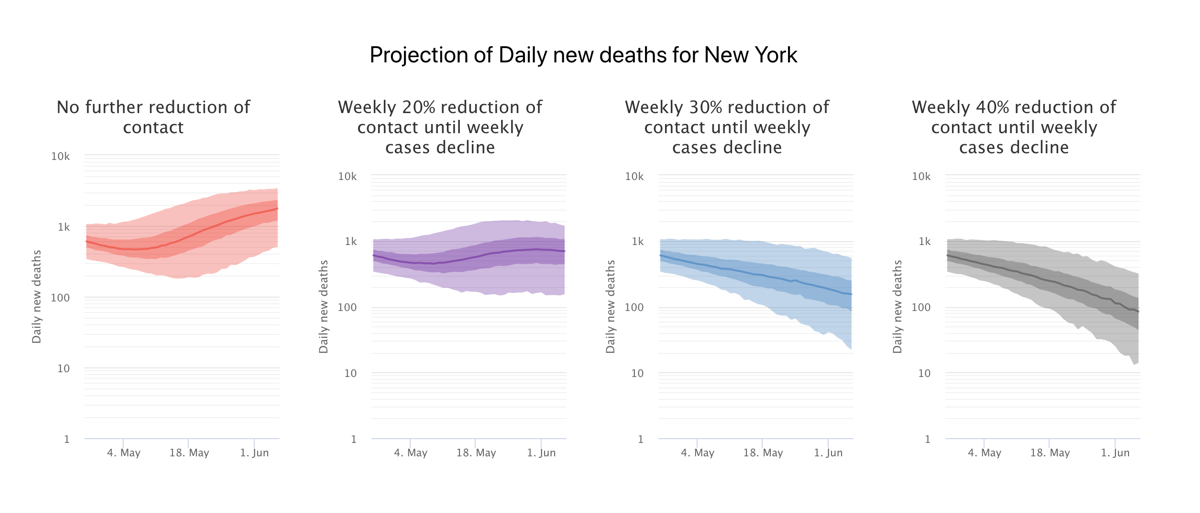
IRA FLATOW: When we look at the different curves of infection in different countries or regions, New, Zealand Italy, the US, can the models explain why they are so different?
JEFFREY SHAMAN: We can certainly estimate differences in how aggressively it’s moving through the population. There are some differences due to population density but they’re not maybe as large as people might think. Certainly, a place like New York City and particularly Manhattan where you have lots of people on top of each other and many, many contacts, you would expect a more aggressive growth with the virus and stronger exponential growth early on potentially than you would in some place like rural Texas.
But as you move across cultures and you move to different societies, you’re running into multiple issues that can make it actually difficult to really estimate what’s going on. Certainly, there are components of the country where it may be introduced and not in others. So for instance, in Italy, it was in Lombardy where they got most of their infections initially. That was the real epicenter of activity for that country.
So it may be worthwhile considering what they have done there and what the population density and characteristics, what the demographics are, how many elderly people they have– Italy has a very aged population. The other things, of course, are that we need to get a sense of what’s going on in terms of policy and compliance with policy and response.
And we’ve had enormous variability from country to country and what they’re doing. New Zealand was very proactive. Sweden has chosen to opt to try for herd immunity for the most part and let the virus essentially roll over them and steamroll them. We have some natural experiments going on.
Certainly, the models can tell us what does this mean the characteristics of the virus over time. What happens to that basic reproductive number? Does it drop off in time because of social distancing practices that we know are in place?
IRA FLATOW: Sarah, earlier I rattled off a few models that people might have seen media coverage. How are we, who are really not trained to study curves and modeling, how are we supposed to digest these numbers? And if they’re the result of math, what kind of trust should we put in them?
SARAH COBEY: That’s a really good question, because you’re right. There are a lot of models that are in development right now. And that’s a great thing. But I can see how also it’s a little awful to watch if this isn’t the sort of thing you’re used to thinking about all the time. I think the good ones are going to be grounded in some understanding of the biological processes.
So they’re going to be transmission models. You know, I think the first thing to do is just to look at what some of the basic assumptions in the model are. And you know, there should be some sort of biological motivation for them. So I think those are the models to trust when you’re thinking about forecast. But of course, those models are forecasting very different things.
And what’s happening here really is there’s so much uncertainty that all of the modelers are dealing with right now. We have uncertainty in the underlying biology, like the role of children. We have uncertainty in the specific transmission rates of parameters in different regions. And then again, we have uncertainty in the quality of the data that we’re working with.
So that– yeah. So that’s where the messiness comes from. But I am sure that as new data come in, and as modelers have a moment to catch their breath and start comparing their model to other models, and there are wonderful initiatives to do this comparison, that we’re going to see more convergence and more of a consensus.
IRA FLATOW: I’m Ira Flatow. And this is “Science Friday” from WNYC Studios. This is, I really think, the first time the public has been inundated with waves, and graphs, and things, and modeling. Do you think they’re coming away with a better understanding of modeling?
SARAH COBEY: Yeah. I would love to know the answer to that question. I hope that by listening to shows such as this one that the public is coming away with a better impression and a deeper understanding of modeling. I’m quite worried about some of the models. And one particular model that has received a lot of attention and, in particular, a lot of attention from the White House that I think is not going to be one of the more reliable, useful models going forward– and I hope that there can be a shift toward the wider diversity of models that are out there and especially the models that are being produced by people who’ve been doing this for decades.
IRA FLATOW: So Sarah, are you saying that the White House predictions are not very helpful because they change all the time?
SARAH COBEY: I’m saying that the main model that they relied on, yes, is a very poor model that is very brittle and is very statistical model that does not capture the underlying process. And so yes, the predictions change frequently, like daily, and dramatically often.
IRA FLATOW: People are already talking about a second wave coming this fall. Is there any way to predict whether our actions today, whether it’s social distancing or what, might predict what a second wave might look like?
JEFFREY SHAMAN: Ira, it’s a very difficult question. We’ve had this novel infectious agent dropped into our midst. But we really have an incomplete picture of it. And unfortunately, some of that incompleteness factors into the question that you asked. We don’t know, for instance, if this virus truly is seasonal.
Other endemic coronaviruses are. They peak in the northern hemisphere in January, February just like the flu. If this virus were to follow that pattern, we might see an ablation, a diminution of the transmissibility of the virus in July and August and catch a break from here it in the United States. And that then may peel back as we get into colder and drier months in the fall. And that may encourage a wave, a second wave, such as what we’ve seen with pandemic influenza. But we don’t know if that’s really the case.
And layered on that again are all these sociological uncertainties. If we get a break from it for a while, are we then going to start frequenting restaurants, and open businesses, and get too much back to normal? And then as the transmissibility of the virus increases again, are we going to see a second wave? And even without seasonality associated with it, those same processes may come into effect.
You know, right now Georgia has reopened its movie theaters, and nail salons, and restaurants. But not all the businesses are opening. Some of them are too cautious about it and they’re concerned about the virus so they don’t. And not all the clientele are even going to go in and fill those restaurants. But if this experiment goes forward and they don’t see a rapid rebound in cases, the confidence to go and go out to a restaurant and go to a movie theater is going to increase.
And more and more people are going to utilize them. The unfortunate reality though is that there are these delays baked into the system in which a person who inquires the infection today won’t be confirmed, if they do become symptomatic and seek clinical care, for another week or two. And that gives the virus a couple of weeks to actually take off for all time.
So we’re in some very risky areas right now. And for both social reasonings, for relaxation of social distancing, and the way we behave and interact, as well as maybe due to this innate seasonality if it does exist, we could see second waves or third waves.
SARAH COBEY: This is where actually we’re getting to a whole new level of modeling that most of us in the infectious disease world, we don’t have a lot of experience in that. I think we basically choose when the second wave is going to happen in the sense that it’s so determined by changes in our own behavior.
And we’re clearly dealing with a response to an infectious disease outbreak that is unprecedented in its magnitude right now. And so it is going to be tricky, I think, for any model right now to say what’s going to happen in late summer or the fall because you somehow have to be able to forecast policy at the same time and also forecast responses to that policy.
So I hope that people can appreciate that complexity, while simultaneously understanding that there are certain fundamental biological processes that almost all the models do agree on, one of them being, for instance, that unless there is a very strong seasonal depression in transmission rates that’s occurring in the summer in the northern hemisphere, if we pull back on a lot of these interventions and try to go back to business as usual, there’s almost certainly going to be a second wave almost immediately.
IRA FLATOW: I want to thank both of you this hour, Dr. Jeffrey Shaman professor of environmental health science and director of the Climate and health program at Columbia University in New York, and Dr. Sarah Cobey, associate professor of ecology and evolution at the University of Chicago. Thank you both for taking time to be with us today.
SARAH COBEY: Thank you.
JEFFREY SHAMAN: Thank you for having us.
Copyright © 2020 Science Friday Initiative. All rights reserved. Science Friday transcripts are produced on a tight deadline by 3Play Media. Fidelity to the original aired/published audio or video file might vary, and text might be updated or amended in the future. For the authoritative record of Science Friday’s programming, please visit the original aired/published recording. For terms of use and more information, visit our policies pages at http://www.sciencefriday.com/about/policies/
Christie Taylor was a producer for Science Friday. Her days involved diligent research, too many phone calls for an introvert, and asking scientists if they have any audio of that narwhal heartbeat.
Ira Flatow is the founder and host of Science Friday. His green thumb has revived many an office plant at death’s door.